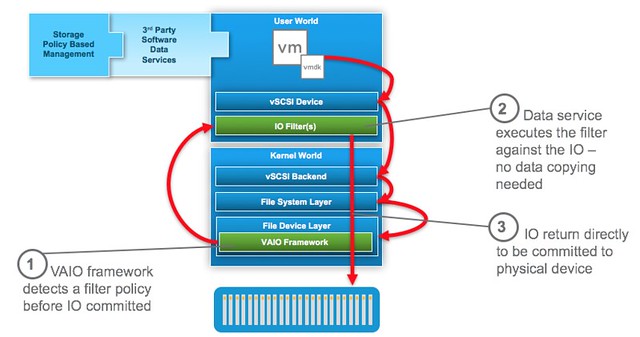
I just wanted to add this pointer, if you are a vSAN and VROps customer then it is good to know that there is a new pack for vSAN. You need to be running vSAN 6.2 or 6.5 and VROps 6.4. It is a dedicated vSAN Management Pack by the way, which has as advantage for us (and you) that we will be able to iterate faster based on your needs.
You can find it here: https://solutionexchange.vmware.com/store/products/vmware-vrealize-operations-management-pack-for-vsan
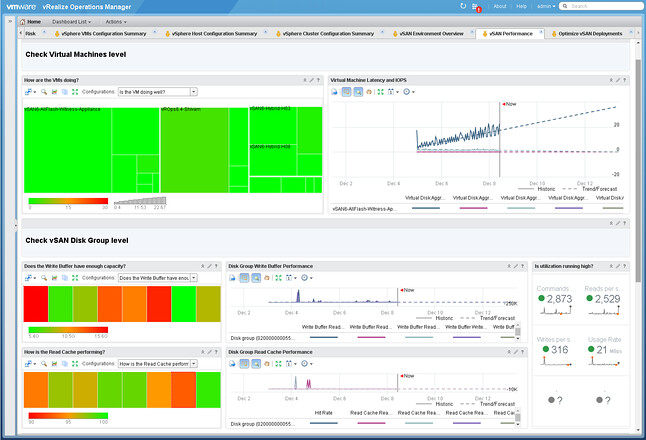
 I was driving back home from Germany on the autobahn this week when thinking about 5-6 conversations I have had the past couple of weeks about performance tests for HCI systems. (Hence the pic on the rightside being very appropriate ;-)) What stood out during these conversations is that many folks are repeating the tests they’ve once conducted on their legacy array and then compare the results 1:1 to their HCI system. Fairly often people even use a legacy tool like Atto disk benchmark. Atto is a great tool for testing the speed of your drive in your laptop, or maybe even a RAID configuration, but the name already more or less reveals its limitation: “disk benchmark”. It wasn’t designed to show the capabilities and strengths of a distributed / hyper-converged platform.
I was driving back home from Germany on the autobahn this week when thinking about 5-6 conversations I have had the past couple of weeks about performance tests for HCI systems. (Hence the pic on the rightside being very appropriate ;-)) What stood out during these conversations is that many folks are repeating the tests they’ve once conducted on their legacy array and then compare the results 1:1 to their HCI system. Fairly often people even use a legacy tool like Atto disk benchmark. Atto is a great tool for testing the speed of your drive in your laptop, or maybe even a RAID configuration, but the name already more or less reveals its limitation: “disk benchmark”. It wasn’t designed to show the capabilities and strengths of a distributed / hyper-converged platform.