This is the moment you all have been waiting for, vSphere 8.0 was just announced. There are some great new features and capabilities in this release, and in this blog post I am going to be discussing some of these.
First of all, vSphere Distributed Services Engine. What is this? Well basically it is Project Monterey. For those who have no idea what Project Monterey is, it is VMware’s story around SmartNICs or Data Processing Units (DPUs) as they are typically called. These devices are basically NICs on steroids, NICs with a lot more CPU power, memory capacity, and bandwidth/throughput. These devices not only enable you to push more packets and do it faster, they also provide the ability to run services directly on these cards.
Services? Yes, with these devices you can for instance offload NSX services from the CPU to the DPU. This not only brings NSX to the layer where it belongs, the NIC, it also frees up x86 cycles. Note, that in vSphere 8 it means that an additional instance of ESXi is installed on the DPU itself. This instance is managed by vCenter Server, just like your normal hosts, and it is updated/upgraded using vLCM. In other words, from an operational perspective, most will be familiarized fast. Now having said that, in this first release, the focus very much is on acceleration, not as much on services.
The next major item is Tanzu Kubernetes Grid 2.0. I am not the expert on this, Cormac Hogan is, so I want to point everyone to his blog. What for me probably is the major feature that this version brings is Workload Availability Zones. It is a feature that Frank, Cormac, and I were involved in during the design discussions a while back, and it is great to finally see it being released. Workload Availability Zones basically enable you to deploy a Tanzu Kubernetes Cluster across vSphere Clusters. As you can imagine this enhances resiliency of your deployment, the diagram below demonstrates this.

For Lifecycle Management also various things were introduced. I already mentioned the vLCM now support DPUs, which is great as it will make managing these new entities in your environment so much easier. vLCM now also can manage Stand Alone Host’s via the API, and vLCM can remediate hosts placed into maintenance mode manually now as well. Why is this important? Well this will help customers who want to remediate hosts in parallel to decrease the maintenance window. For vCenter Server lifecycle management, there also was a major improvement. vSphere 8.0 now has the ability to store the vCenter Server cluster state in a distributed key-value store running on the ESXi hosts in the cluster. Why would it do this? Well it basically provides the ability to roll back to the last known state since the last backup. In other words, if you added a host to the cluster after the last backup, this is now stored in the distributed key-value store. When a backup is then restored after a failure, vCenter and the distributed key-value store will then sync so that the last known state is restored.
Last lifecycle management-related feature I want to discuss is vSphere Configuration Profiles. vSphere Configuration Profiles is a feature that is released as Tech Preview and over time will replace Host Profiles. vSphere Configuration Profiles introduces the “desired-state” model to host configuration, just like vLCM did for host updates and upgrades. You define the desired state, you attach it to a cluster and it will be applied. Of course, the current state and desired state will be monitored to prevent configuration drift from occurring. If you ask me, this is long overdue and I hope many of you are willing to test this feature and provide feedback so that it can be officially supported soon.
For AI and ML workload a feature is introduced which enables you to create Device Groups. What does this mean? It basically enables you to logically link two devices (NIC and GPU, or GPU and GPU) together. This is typically done with devices that are either linked (GPUs for instance through something like NVIDIA NVLINK) or a GPU and a NIC which are tightly coupled as they are on the same PCIe Switch connected to the same CPU, bundling these and exposing them as a pair to a VM (through Assignable Hardware) with an AI/ML workload simply optimizes the communication/IO as you avoid the hop across the interconnect as shown in the below diagram.

On top of the above firework, there are also many new smaller enhancements. Virtual Hardware version 20 for instance is introduced, and this enables you to manage your vNUMA configuration via the UI instead of via advanced settings. Also, full support for Windows 11 at scale is introduced by providing the ability to automatically replace the required vTPM device when a Windows 11 VM is cloned, ensuring that each VM has a unique vTPM device.
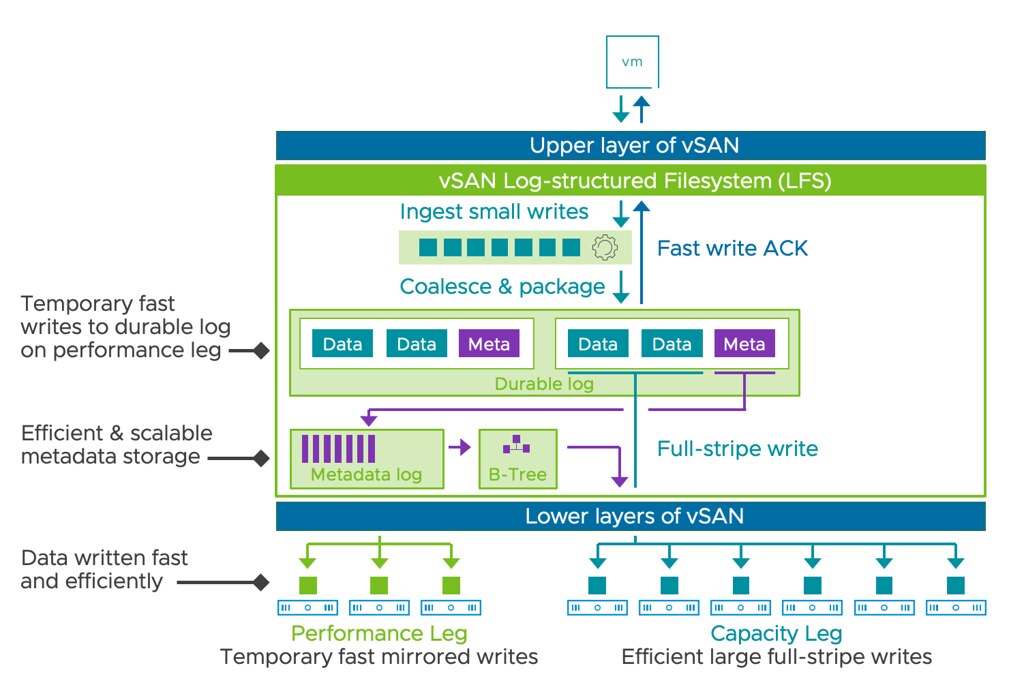
There’s more, and I would like to encourage you to read the material on core.vmware.com/vsphere, and for TKG read Cormac’s material! I also highly recommend this post about what is new for core storage.
")