Instead of one generic post with a bunch of data I picked a couple of features and dug a little bit deeper, today I will be discussing what is new for HA in vSphere 6.0. Lets start with a list and then look at the features / enhancements individually:
- Support for Virtual Volumes – With Virtual Volumes a new type of storage entity is introduced in vSphere 6.0.
- VM Component Protection – This allows HA to respond to a scenario where the connection to the virtual machine’s datastore is impacted temporarily or permanently.
- “Response for Datastore with All Paths Down”
- “Response for Datastore with Permanent Device Loss”
- Increased scale – Cluster limit has grown from 32 to 64 hosts and to a max of 8000 VMs per cluster
- Registration of “HA Disabled” VMs on hosts after failure
Lets start with support for Virtual Volumes. It may sound like this is a given but as the whole concept of a VMFS volume no longer exists with Virtual Volumes and VMs have “virtual volumes” instead of VMDKs you can imagine that some work was needed to allow for HA to restart virtual machines stored on a VVOL enabled storage system.
VM Component Protection (VMCP) is in my opinion THE big thing that got added to vSphere HA. What this feature basically allows you to do is protect yourself against storage failures. There are two types of failures VMCP will respond to and those are PDL and APD. Before we look at some of the details, I want to point out that configuring is extremely simple… Just one tickbox to enable it.
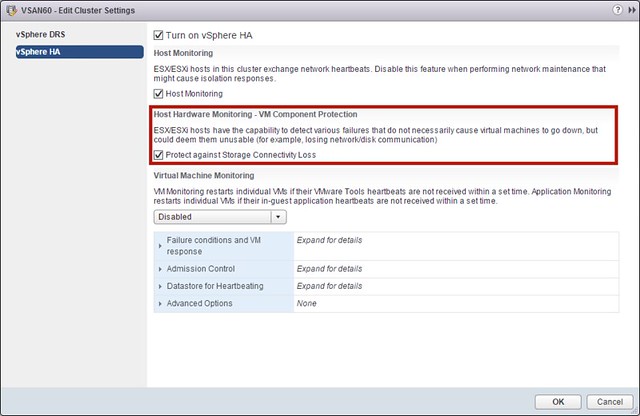
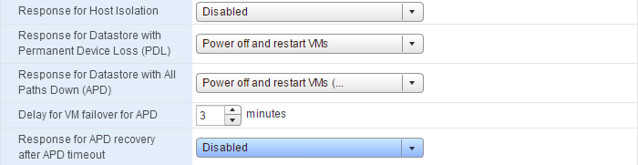
In the case of a PDL (permanent device loss), this is something HA already was capable of doing when configured through the command line, a VM will be restarted instantly when a PDL signal is issued by the storage system. For an APD (all paths down) this is a bit different. A PDL more or less indicates that the storage device does not expect the device to return any time soon. An APD is more of an unknown situation, it may return… it may not… and no clue how long it takes. With vSphere 5.1 some changes were introduced to the way APD is handled by the hypervisor in this mechanism is leveraged by HA to allow for a response. (Cormac wrote an excellent post about this APD handling here.) When an APD occurs a timer starts. After 140 seconds the APD is declared and the device is marked as APD time out. When the 140 seconds has passed HA will start counting. The HA time out is 3 minutes. When the 3 minutes has passed HA can restart the virtual machine, but you can configure VMCP to respond differently if you want it to. You could for instance specify that events are issued that a PDL or APD has occurred. You can also specify how aggressively HA needs to try to restart VMs that are impacted by an APD. Note that aggressive / conservative refers to the likelihood of HA being able to restart VMs. When set to “conservative” HA will only restart the VM that is impacted by the APD if it knows another host can restart it. In the case of “aggressive” HA will try to restart the VM even if it doesn’t know the state of the other hosts, which could lead to a situation where your VM is not restarted as there is no host that has access to the datastore the VM is located on. It is also good to know that if the APD is lifted and access to the storage is restored during the total of roughly 5 minutes and 20 seconds it would take to reboot the VM, that HA will not do anything unless you explicitly configure it do so. This is where the “Response for APD recovery after APD timeout” comes in to play.
Increased scale is pretty straight forward, from 32 to 64 hosts and a total of 8000 VMs per cluster. I don’t know too many customers hitting this boundaries but I do come across a request like this occasionally. So if you want to grow your cluster, you can now do so. Do note that you may hit other limits like the LUN limit or the VM limit or…
Registration of HA Disabled VMs after a failure is a feature I have requested a long time ago. I am glad to see this made it in to the release. Basically when you have HA disabled on a specific VM this feature will make sure that the VM gets registered on another host after a failure. This will allow you to easily power-on that VM when needed without needed to manually re-register it yourself. Note, HA will not do a power-on of the VM but it will just register it for you.
That was it for now…


 I am very pleased to see VMware just announced the beta of vSphere. I think it is great that everyone has the chance to sign up, download it, test it and provide feedback on such a critical part of your environment! Who doesn’t love to play with cutting edge technology? I know I do! Especially for all the bloggers and book authors out there this is an excellent opportunity to already start working on articles (or a book) for the launch time frame, whenever that will be. I have my engines fired up, downloading the bits as I write this…
I am very pleased to see VMware just announced the beta of vSphere. I think it is great that everyone has the chance to sign up, download it, test it and provide feedback on such a critical part of your environment! Who doesn’t love to play with cutting edge technology? I know I do! Especially for all the bloggers and book authors out there this is an excellent opportunity to already start working on articles (or a book) for the launch time frame, whenever that will be. I have my engines fired up, downloading the bits as I write this…