Last week I was briefed by Runecast (together with Cormac) on the new version, Runecast 2.0, which was released/announced today. I always enjoy talking to Stan as every time we talk they have something new which surprises me, or he tells me about something cool on the roadmap. For those who did not read my previous articles, Runecast is a company which focusses on analyzing VMware environments and assess the environment on potential issues. These issues could be anything ranging from configuration issues, driver/firmware issue, to security issues. It reminds me very much of what we have with vSAN which is the health check. The big difference though is that this solution includes many more checks and doesn’t just focus on vSAN but on many different parts of the stack. Just to give you an idea, today Runecast can analyze your vSphere environment up to vSphere 6.7 and can also analyze vSAN and NSX-V. The cool thing is that it also does this “offline”, they have an appliance and regular updates (rules and features) and this means that even in a dark site this would work.
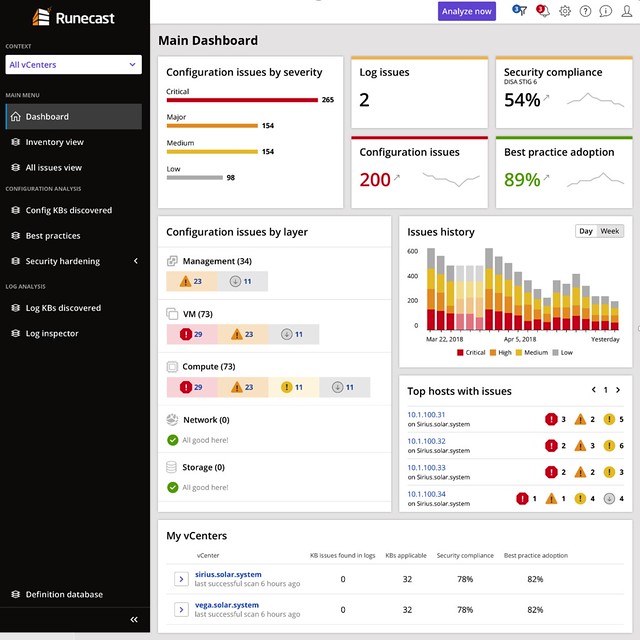
A lot of Runecast’s customers are either in the financial space or government space. I guess this is also why their focus for the 2.0 version was primarily on PCI-DSS. With over 200 technical checks, which map against PCI-DSS requirements, they (as Runecast told me) have by far the largest collection of requirements in an automated analyzer (for VMware) in the industry. Definitely, a smart enhancement, if you are not interested in PCI-DSS, you can simply disable the whole check and it will never show up in your interface. You can also, if only a limited number of clusters should be validated, filter out certain results.
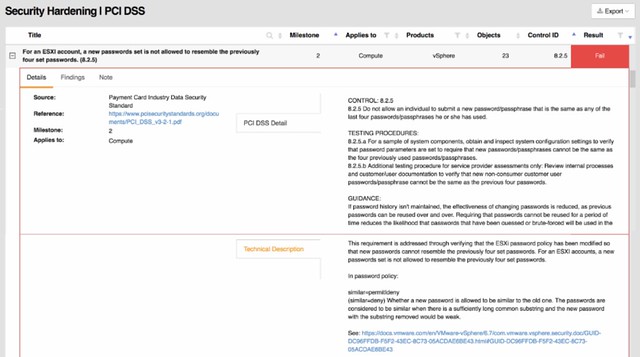
The 20 version of Runecast also comes with a lot of updates around the appliance, now I consider these “internals” as for most customers it is not relevant in terms of the value it offers, but it is important to know from a security perspective I guess.
This version also introduces a historical perspective. Meaning that starting with Runecast 2.0 the historical information of checks is stored. This will allow you to see some form of trending when it comes to the different checks/validations. You could for instance now track if you do updates and maintenance if the number of potential issues is going down. You could also task someone with validating the reported issues and fixing those when or where possible. This should over time improve the availability, reliability, and security of your environment.
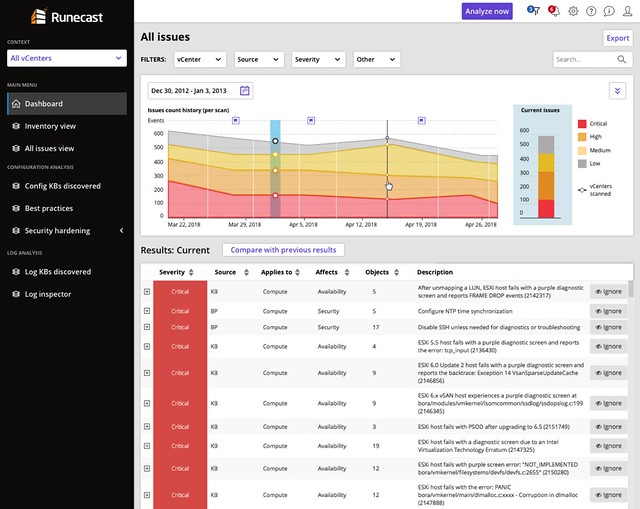
Last but not least the UI has been fully overhauled. They redesigned it just to make it easier to read and understand. Also, a couple of dashboards were added, which makes sense… a new release means new dashboards!
If you happen to go to VMworld, make sure to stop by their booth and have a look, I think you will find it interesting. Or simply read the Runecast blog, and download the appliance and try it out.
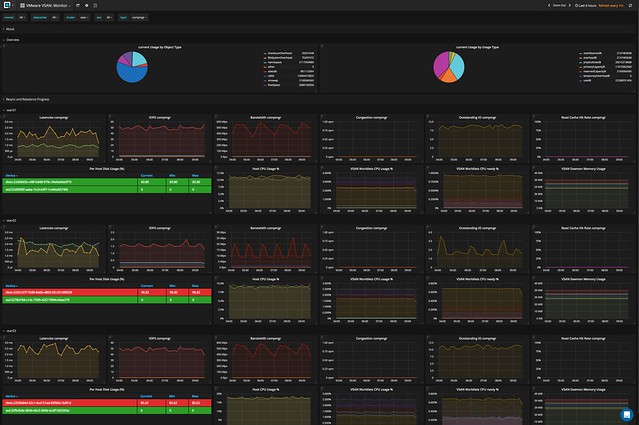
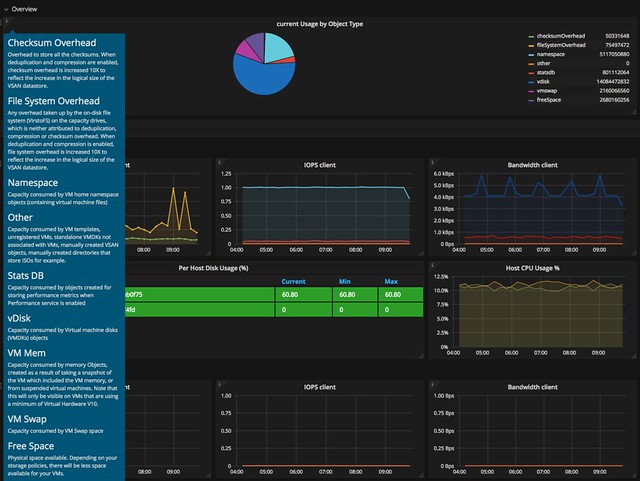
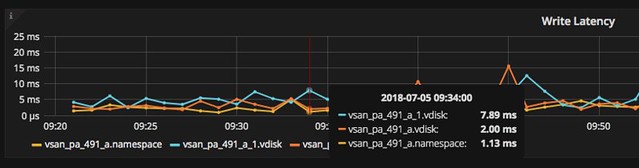
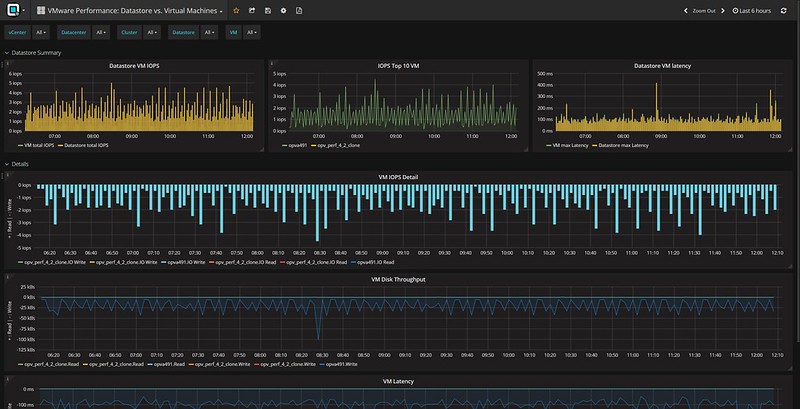

 Last week I presented at the Tech Support Summit in Cork with Cormac. Our session was about the evolution of vSAN, where are we today but more importantly which directly will we be going. One thing that struck me when I discussed vSAN Support Insight, the solution we announced not to long ago, is that not too many people seemed to understand the benefit. When you have vSAN and you enable CEIP (Customer Experience Improvement Program) then you have a phone home solution for your vSphere and vSAN environment automatically. What this brings is fairly simple to explain: less frustration! Why? Well the support team will have, when you provide them your vCenter UUID, instant access to all of the metadata of your environment. What does that mean? Well the configuration for instance, the performance data, logs, health check details etc. This will allow them to instantly get a good understanding of what your environment looks like, without the need for you as a customer to upload your logs etc.
Last week I presented at the Tech Support Summit in Cork with Cormac. Our session was about the evolution of vSAN, where are we today but more importantly which directly will we be going. One thing that struck me when I discussed vSAN Support Insight, the solution we announced not to long ago, is that not too many people seemed to understand the benefit. When you have vSAN and you enable CEIP (Customer Experience Improvement Program) then you have a phone home solution for your vSphere and vSAN environment automatically. What this brings is fairly simple to explain: less frustration! Why? Well the support team will have, when you provide them your vCenter UUID, instant access to all of the metadata of your environment. What does that mean? Well the configuration for instance, the performance data, logs, health check details etc. This will allow them to instantly get a good understanding of what your environment looks like, without the need for you as a customer to upload your logs etc.