Storage has been my primary focus for the 5.0 launch. The question often asked when talking about the separate components is how it all fits together. Lets first list some of the new or enhanced features:
- VMFS-5
- vSphere Storage APIs – Array Integration aka VAAI
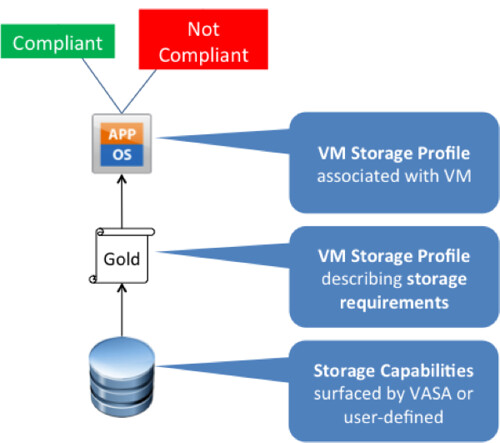
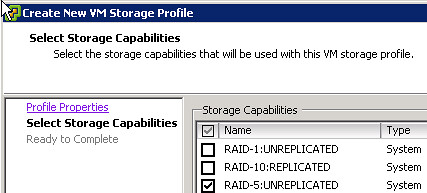
- vSphere Storage APIs – Storage Awareness aka VASA
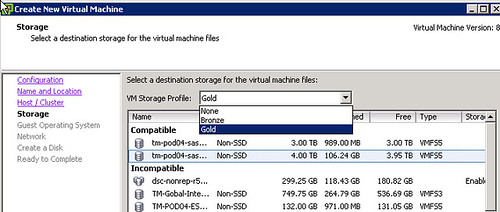
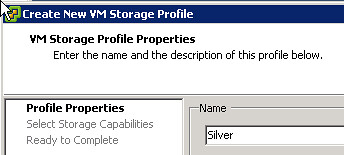
- Profile-Driven Storage (VM Storage Profiles in the GUI)
- Storage I/O Control
- Storage DRS
I wrote separate articles about all of these features and hopefully you have read them and already see the big picture. If you don’t than this is a good opportunity to read them or head over to the vSphere Storage Blog for more details on some of these.. I guess the best way to explain it is by using an example of what life could be like when using all of these new or enhanced features compared to what is used to be like:
The Old Way: Mr Admin is managing a large environment and currently has 300 LUNs each being 500GB divided across three 8 hosts clusters. He is maintaining a massive spreadsheet with storage characteristics and runs scripts to validate virtual machines are place on the correct tier of storage. He is leveraging SIOC to avoid the noisy neighbor problem and leveraging the VAAI primitives to offload some of the tasks to the array. Still he spends a lot of time waiting, monitoring, managing virtual machines and datastores.
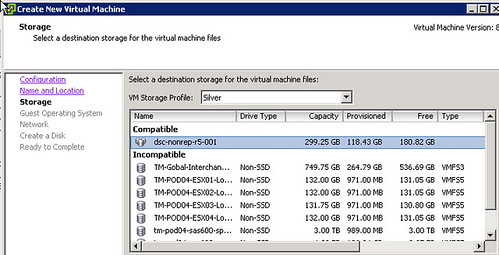
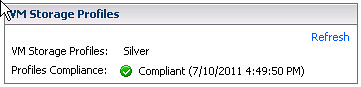
vSphere 5.0: Mr Admin is managing a large environment and currently has 60 thin provisioned 2.5TB LUNs presented to a single cluster. Mr Admin defines several storage tiers using VM Storage Profiles detailing storage characteristics provided through VASA. Per tier based on the information provided through VASA a Datastore Cluster is created. Datastore Clusters form the basis of Storage DRS and Storage DRS will be responsible for initial placement and preventing both IO and diskspace bottlenecks in your environment. As Storage IO Control is automatically enabled when SDRS IO balancing is enabled the noisy neighbor problem will also be eliminated. When provisioning a new virtual machine Mr Admin simple picks the appropriate VM Storage Profile and selects the compliant Datastore Cluster. If in any case Storage DRS would move things around, the “Reclaim Dead Space” feature of VAAI is used to unmap the blocks from the source datastore so that these can be re-used if and when needed.
No more spreadsheets, no extensively monitoring diskspace / latency, no more manual validation of virtual machine placement… It is all about ease of management, reducing operational effort and offloading tasks to vCenter or even your storage array!