Frank and I published the book this morning and Amazon was extremely fast with getting it up on the website. It is available now:

by Duncan Epping
Frank and I published the book this morning and Amazon was extremely fast with getting it up on the website. It is available now:
Frank and I had been talking about this for a couple of months, but without mentioning what it was we were working on. The last couple of months we’ve spent our spare time on updating the 5.0 Clustering Deepdive to 5.1.
Although this “just” an update to 5.1, we’ve added a section about stretched clustering to the book and the Storage DRS section has been completely overhauled. Several new paragraphs were added to the vSphere HA section and we had to do some minor tweaks to the vSphere DRS section. On top of we added a great foreword by Raghu Raghuram!
In the upcoming week the book will be available on Amazon (paper – kindle) and in the Apple iBooks store. As we needed to be careful with publishing it at a certain time/date in some cases it might take a couple of days before it shows up in your “local” online bookstore. If you really can’t wait, it is available now on Createspace.
Again, we have kept the prices low… The e-book will sell for only $ 7.49 (note a surcharge might be added based on location) and the paper copies sells for $ 24.95. It is a bargain if I say so myself. Note that even the paper copy will be available directly from European Amazon stores and so will the ebook.
For those at VMworld, there are copies available at the VMworld store on Tuesday, or maybe even Monday afternoon. Note that there is a limited amount available… if you want a copy I would recommend picking it up soon! If you see Frank or myself walking around and would love to have your book signed, don’t hesitate it is our pleasure! We had the honor of presenting the book to Carl Eschenbach yesterday, I can tell you Carl was thrilled and so are we… P i c k i t u p!

I just noticed I never blogged about a white paper Frank Denneman and I co-authored. The white paper deals about interoperability between Storage DRS and various other products and features. I highly recommend reading it if you are planning on implementing Storage DRS or want to get a better understanding of how Storage DRS interacts with other components of your infrastructure.
Storage DRS interoperability
This document presents an overview of best practices for customers considering the implementation of VMware vSphere Storage DRS in combination with advanced storage device features or other VMware products.
Today someone asked for a Storage DRS intro, I wrote one for our book a year ago and figured I would share it with the world. I still feel that Storage DRS is one of the coolest features in vSphere 5.0 and I think that everyone should be using this! I know there are some caveats (1, 2) when you are using specific array functionality or for instance SRM, but nevertheless… this is one of those features that will make an admin’s life that much easier! If you are not using it today, I highly suggest evaluating this cool feature.
*** out take from the vSphere 5.0 Clustering Deepdive ***
vSphere 5.0 introduces many great new features, but everyone will probably agree with us that vSphere Storage DRS is most the exciting new feature. vSphere Storage DRS helps resolve some of the operational challenges associated with virtual machine provisioning, migration and cloning. Historically, monitoring datastore capacity and I/O load has proven to be very difficult. As a result, it is often neglected, leading to hot spots and over- or underutilized datastores. Storage I/O Control (SIOC) in vSphere 4.1 solved part of this problem by introducing a datastore-wide disk-scheduler that allows for allocation of I/O resources to virtual machines based on their respective shares during times of contention.
Storage DRS (SDRS) brings this to a whole new level by providing smart virtual machine placement and load balancing mechanisms based on space and I/O capacity. In other words, where SIOC reactively throttles hosts and virtual machines to ensure fairness, SDRS proactively makes recommendations to prevent imbalances from both a space utilization and latency perspective. More simply, SDRS does for storage what DRS does for compute resources.
There are five key features that SDRS offers:
Resource aggregation enables grouping of multiple datastores, into a single, flexible pool of storage called a Datastore Cluster. Administrators can dynamically populate Datastore Clusters with datastores. The flexibility of separating the physical from the logical greatly simplifies storage management by allowing datastores to be efficiently and dynamically added or removed from a Datastore Cluster to deal with maintenance or out of space conditions. The load balancer will take care of initial placement as well as future migrations based on actual workload measurements and space utilization.
The goal of Initial Placement is to speed up the provisioning process by automating the selection of an individual datastore and leaving the user with the much smaller-scale decision of selecting a Datastore Cluster. SDRS selects a particular datastore within a Datastore Cluster based on space utilization and I/O capacity. In an environment with multiple seemingly identical datastores, initial placement can be a difficult and time-consuming task for the administrator. Not only will the datastore with the most available disk space need to be identified, but it is also crucial to ensure that the addition of this new virtual machine does not result in I/O bottlenecks. SDRS takes care of all of this and substantially lowers the amount of operational effort required to provision virtual machines; that is the true value of SDRS.
However, it is probably safe to assume that many of you are most excited about the load balancing capabilities SDRS offers. SDRS can operate in two distinct modes: No Automation (manual mode) or Fully Automated. Where initial placement reduces complexity in the provisioning process, load balancing addresses imbalances within a datastore cluster. Prior to vSphere 5.0, placement of virtual machines was often based on current space consumption or the number of virtual machines on each datastore. I/O capacity monitoring and space utilization trending was often regarded as too time consuming Over the years, we have seen this lead to performance problems in many environments, and in some cases, even result in down time because a datastore ran out of space. SDRS load balancing helps prevent these, unfortunately, common scenarios by making placement recommendations based on both space utilization and I/O capacity when the configured thresholds are exceeded. Depending on the selected automation level, these recommendations will be automatically applied by SDRS or will need to be applied by the administrator.
Although we see load balancing as a single feature of SDRS, it actually consists of two separately-configurable options. When either of the configured thresholds for Utilized Space (80% by default) or I/O Latency (15 milliseconds by default) are exceeded, SDRS will make recommendations to prevent problems and resolve the imbalance in the datastore cluster. In the case of I/O capacity load balancing, it can even be explicitly disabled.
Before anyone forgets, SDRS can be enabled on fully populated datastores and environments. It is also possible to add fully populated datastores to existing datastore clusters. It is a great way to solve actual or potential bottlenecks in any environment with minimal required effort or risk.
Datastore Maintenance Mode is one of those features that you will typically not use often; you will appreciate it when you need. Datastore Maintenance Mode can be compared to Host Maintenance Mode: when a datastore is placed in Maintenance Mode all registered virtual machines, on that datastore, are migrated to the other datastores in the datastore cluster. Typical use cases are data migration to a new storage array or maintenance on a LUN, such as migration to another RAID group.
Affinity Rules enable control over which virtual disks should or should not be placed on the same datastore within a datastore cluster in accordance with your best practices and/or availability requirements. By default, a virtual machine’s virtual disks are kept together on the same datastore.
For those who want more details, Frank Denneman wrote an excellent series about Datastore Clusters which might interest you:
Part 1: Architecture and design of datastore clusters.
Part 2: Partially connected datastore clusters.
Part 3: Impact of load balancing on datastore cluster configuration.
Part 4: Storage DRS and Multi-extents datastores.
Part 5: Connecting multiple DRS clusters to a single Storage DRS datastore cluster.
Part 6: Aggregating datastores from multiple storage arrays into one Storage DRS datastore cluster.
Some other articles that might be of use:
The following video will give an overview of the above mentioned features… worth checking.
On my blog article for yesterday “Rob M” commented that the default affinity rule for Storage DRS (SDRS), keep VM files together, did not make sense to him. One of the reasons this affinity rule is set is because customers indicated that from an operational perspective it would be easier if all files of a given VM (vmx / vmdk’s) would reside in the same folder. Especially troubleshooting was one of the main reasons, as this lowers complexity. I have to say that I fully agree with this, I’ve been in the situation where I needed to recover virtual machines and having them spread across multiple datastore really complicates things.
But, just like Rob, you might not agree with this and rather have SDRS handling balancing on a file per file basis. That is possible and we documented this procedure in our book. I was under the impression that I blogged this, but just noticed that somehow I never did. Here is how you change the affinity rule for the current provisioned VMs in a datastore cluster:
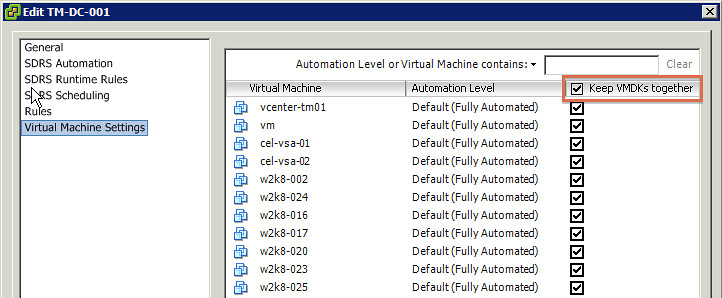
Also check out this article by Frank about DRS/SDRS affinity rules, useful to know!