Storage DRS must be one of the most under-appreciated features that is part of vSphere. For whatever reason it doesn’t get the airtime it deserves, not even from VMware folks which is a shame if you ask me. I was reading the What’s New material for vSphere 6.0 and I noticed that the “What is new for Storage DRS in vSphere 6.0” was completely missing. I figured I would do a quick write up of what has been improved and introduced for SDRS in 6.0 as some of the enhancements are quite significant! Lets start with a list and then look at these enhancements in more detail:
- Deep integration with vSphere APIs for Storage Awareness (VASA)
- Site Recovery Manager integration
- vSphere Replication integration
- Integration with Storage Policy Based Management
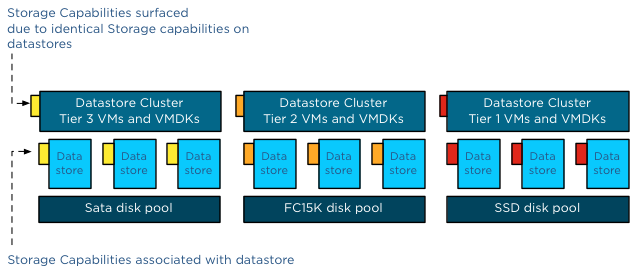
Lets start with the top one, deep integration with vSphere APIs for Storage Awareness (VASA) as that is the biggest improvement if you ask me. What the integration with VASA results in is fairly straight forward, when the VASA plugin for your storage system is configured then Storage DRS will understand what capabilities are enabled on your storage system and more specific your datastores. For example: when using Storage DRS previously on a deduplicated datastore it could happen that the migration initiated by Storage DRS had a negative result on the total available capacity on your storage system. This would be caused by the fact that the deduplication ratio was lower on the destination then it was on the source. Not a very pleasant surprise you can imagine. Also when for instance VMs are snapshotted from a storage system point of view or datastores are replicated… you can imagine that there would be an impact when moving a VM around in that scenario. With 6.0 Storage DRS is capable of understanding:
- Array-based thin-provisioning
- Array-based deduplication
- Array-based auto-tiering
- Array-based snapshot
- Array-based replication
I guess you get the drill, SDRS is now fully capable of understanding the array capabilities and will make balancing decisions taking these capabilities in to consideration. For instance in the case of replication, when replication is enabled and your datastore is part of a consistency group then SDRS will ensure that the VM is only migrated to a datastore which belongs to the same consistency group! For deduplication this is the opposite by the way, in this case SDRS will be informed about which datastores belong to which deduplication domains and when datastores belong to the same domain it will know that moving between those datastores will have little to no effect on capacity. Depending on the level of detail the storage vendor provides through VASA SDRS will even be aware of how efficient the deduplication process is for a given datastore. (Not a VASA requirement, rather a recommendation so results may vary per vendor implementation) Auto-tiering is also an interesting one as this is something that comes up regularly. In this scenario with previous versions of SDRS it could happen that SDRS was moving VMs while the auto-tier array was just promoting or demoting blocks to a lower or higher tier. As you can imagine not a desired scenario and with the VASA integration this can be prevented from happening.
Second big thing is Site Recovery Manager and vSphere Replication integration. I already mentioned the consistency group awareness, of course this is also part of the SRM integration and when VMs are protected by SRM then SDRS will make sure that those VMs are only moved within their consistency group. If for whatever reason there is no way to move within a consistency group then SDRS as a second option can move VMs between datastores which are part of the same SRM Protection Group. Note that this could have an impact though on your workloads! SDRS of course will never automatically move a VM from a replicated to a non-replicated datastore. In fact, there is a strict hierarchy of what type of moves can be recommended:
- Moves within the same consistency group
- Moves across consistency groups, but within the same protection group
- Moves across protection groups
- Moves from a replicated datastore to non-replicated
Note that SDRS will try option 1 first, if it fails, will try option 2, if that fails will try option 3, and so on. Under no circumstances is a recommendation in the category of 2, 3 or 4 executed automatically. You will receive a warning after which you can manually apply the recommendation. This is done to ensure the administrator has full control and full awareness of the migration and can apply it during maintenance or during non-peak hours.
With regards to vSphere Replication also a lot has changed. So far there was no support for vSphere Replication enabled VMs to be part of an SDRS datastore cluster but with 6.0 it is fully supported. As of 6.0 Storage DRS will recognize replica VMs (which are replicated using vSphere Replication) and thresholds have been exceeded then SDRS will query vSphere Replication and will be able to migrate replicas to solve the resource constraint.
Up next the integration with Storage Policy Based Management. In the past when you had different tiers of datastores as part of the same Datastore Cluster then SDRS could potentially move a VM which was assigned policy “gold” to a datastore which was associated with a “silver” policy. With vSphere 6.0, SDRS is aware of storage policies in SPBM and will only move or place VMs to a datastore that can satisfy that VM’s storage policy.
Oh and before I forget, there is also the introduction of IOPS reservations on a per virtual disk level. This isn’t really part of Storage DRS but a function of the mClock scheduler and integrated with Storage IO Control and SDRS where needed. It isn’t available in the UI even in this release, only exposed through the VIM API so I doubt many of you will use it… figured though I would mention it already, and I will do a deeper write up later this week probably.