Episode 004 is out! This time we talk to Cody Hosterman, Director of Product Management at Pure Storage, about Virtual Volumes aka vVols! Cody shares with us the past, present, and future of vVols. I especially enjoyed his explanations around the benefits of vVols for traditional and cloud-native workload. It is also great to hear that VMware is working with Pure Storage on designing and developing a stretched cluster capability for vVols based environments. Listen below, or via Apple, Google, Spotify etc.
nfs
HCI3041BU: Introducing Scalable File Storage on vSAN
Another beta announcement last week for vSAN was around Native File Services. This was the topic of HCI3041BU, which was titled “Introducing Scalable File Storage on vSAN with Native File Services”. The full session can be found here, the summary is below for your convenience. The session was by Venkat Kolli (Product Manager) and engineers Rick Spillane and Wenguang Wang.
Venkat kicks of the session describing the different types of storage most of our customers have in their data center today, and also what kind of data lands on the different types of storage. Basically, it is divided into three main types: Block, File, and Object. Where I personally believe that “object” is at the point of becoming more common on-premises but for many is consumed as a cloud service. Looking at where the data growth is today, it is mainly in the “unstructured data” space.
Next Venkat discusses the management complexity of traditional file storage, not just management complexity but also scaling and forecasting. Which in most cases leads to increased cost. How can vSAN help with simplifying File Services and lowering cost by providing a framework which allows you to serve block, file and object. For now, we are discussing file-services however, but the vision is clear.
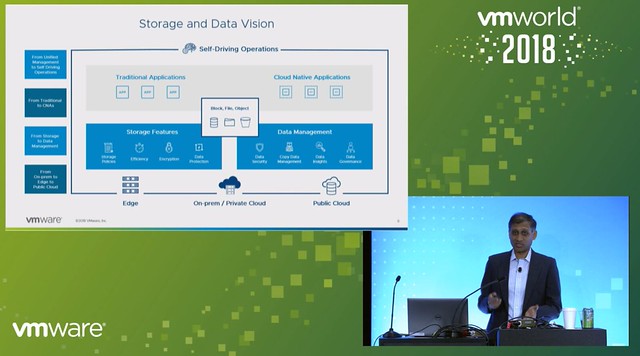
Rick is up next introducing File Services. vSAN File Services allows you to create file shares and provide file services to users/consumers through the same familiar interface you have available today in vSphere. On top of that, you get to leverage the power of policy-based management to provision file shares in a specific way. Which means that File Shares will work in stretched clusters, can be protected with vSAN Data Protection, can be striped/replicated etc. Most important piece of feedback during the design phase from customers was that they did not want a separate storage cluster to manage for file services, this needed to be an integral part of today’s offering.
The requirements and design principles for the vSAN Distributed File System were:
- Elastic Scaling
- Scale IOPs up/down
- Single namespace across the cluster
- Centrally managed, configured and monitored
- Transparent failover
- POSIX File Interface
- Use vSAN services like data path, consensus mechanisms, and checksumming
Rick next explains a new platform that will (potentially) be included in vSAN, this is called the Storage Services Platform. What this provides is stateless containerized frontend servers which sit on top of the vSAN Distributed File System. This will be available for both VMware and partners, so even partners should be able to provide storage services through this platform. Data will sit in the VDFS volumes and then will be exposed through these services. These services, of course, are fully distributed and self-managing.

The Storage Services Platform is implemented in the form of a storage services control plane. This control plane will for instance monitor all front-end servers and node and help in the case of failures, but also will help to ensure availability during maintenance and upgrade. Also, when it comes to scalability the control plane monitors the instances and allows to scale up and down when needed.
Okay, that sounds great, but how do file shares get formed? File shares will be an aggregate of one or multiple vSAN Objects. The great thing about this is that it allows for elasticity in size and performance, plus policies can be associated with these objects. You can now simply create file shares through the UI, or leverage the API. The vSAN team made sure that you can access it and define them the way you prefer. On top of that, this platform will also be available to Kubernetes as part of our Cloud Native Storage Control Plane.
Next Rick briefly discussed data protection for file shares, he mentioned that the team has worked with various 3rd party vendors to allow for full backup and recovery, including file-level restore. What Rick also revealed, surprisingly enough, is that in the initial release we will have:
- NFS v4.1 support
- AD-based Authentication
- Kerberos
- Containerized application support
And in the release after that support for the following is planned:
- SMB
- vSAN DP Integration
- OpenLDAP support
Next Wenguang came up on stage, and he demoed vSAN File Services. He showed how simple it is to enable File Services in the UI. Literally, a couple of steps, provide the networking details and also authentication mechanism. The next step will be to download an OVF, this contains the frontend service we spoke about earlier, for now, this is an NFS server, but this could be other services in the future. After the File Services have been enabled and the OVF is deployed you can start creating file shares. Again this is very straightforward, part of the familiar vSAN UI / HTML-5 interface, which is what I like most, if you know vSAN and/or vSphere you will be able to use vSAN File Services as well. I hope potential other services will be implemented in a similar easy manner.
The Q&A was interesting as well, as some questions around the potential SMB implementation were answered (SAMBA on Linux vs Microsoft vs Dell/EMC stack?) and for instance what block size is used for the file system (4K, like vSAN).
All in all a very exciting solution, and a great overview of what you can expect in the future for vSAN. Note that this is part of the beta, so if you are interested sign up!
vSphere 5.5 U1 patch released for NFS APD problem!
On April 19th I wrote about an issue with vSphere 5.1 and NFS based datastores APD ‘ing. People internally at VMware have worked very hard to root cause the issue and fix it. Log entries witnessed are:
YYYY-04-01T14:35:08.075Z: [APDCorrelator] 9414268686us: [esx.problem.storage.apd.start] Device or filesystem with identifier [12345678-abcdefg0] has entered the All Paths Down state.
YYYY-04-01T14:36:55.274Z: No correlator for vob.vmfs.nfs.server.disconnect
YYYY-04-01T14:36:55.274Z: [vmfsCorrelator] 9521467867us: [esx.problem.vmfs.nfs.server.disconnect] 192.168.1.1/NFS-DS1 12345678-abcdefg0-0000-000000000000 NFS-DS1
YYYY-04-01T14:37:28.081Z: [APDCorrelator] 9553899639us: [vob.storage.apd.timeout] Device or filesystem with identifier [12345678-abcdefg0] has entered the All Paths Down Timeout state after being in the All Paths Down state for 140 seconds. I/Os will now be fast failed.
More details on the fix can be found here: http://kb.vmware.com/kb/2077360
Alert: vSphere 5.5 U1 and NFS issue!
Some had already reported on this on twitter and the various blog posts but I had to wait until I received the green light from our KB/GSS team. An issue has been discovered with vSphere 5.5 Update 1 that is related to loss of connection of NFS based datastores. (NFS volumes include VSA datastores.)
*** Patch released, read more about it here ***
This is a serious issue, as it results in an APD of the datastore meaning that the virtual machines will not be able to do any IO to the datastore at the time of the APD. This by itself can result in BSOD’s for Windows guests and filesystems becoming read only for Linux guests.
Witnessed log entries can include:
2014-04-01T14:35:08.074Z: [APDCorrelator] 9413898746us: [vob.storage.apd.start] Device or filesystem with identifier [12345678-abcdefg0] has entered the All Paths Down state.
2014-04-01T14:35:08.075Z: [APDCorrelator] 9414268686us: [esx.problem.storage.apd.start] Device or filesystem with identifier [12345678-abcdefg0] has entered the All Paths Down state.
2014-04-01T14:36:55.274Z: No correlator for vob.vmfs.nfs.server.disconnect
2014-04-01T14:36:55.274Z: [vmfsCorrelator] 9521467867us: [esx.problem.vmfs.nfs.server.disconnect] 192.168.1.1/NFS-DS1 12345678-abcdefg0-0000-000000000000 NFS-DS1
2014-04-01T14:37:28.081Z: [APDCorrelator] 9553899639us: [vob.storage.apd.timeout] Device or filesystem with identifier [12345678-abcdefg0] has entered the All Paths Down Timeout state after being in the All Paths Down state for 140 seconds. I/Os will now be fast failed.
2014-04-01T14:37:28.081Z: [APDCorrelator] 9554275221us: [esx.problem.storage.apd.timeout] Device or filesystem with identifier [12345678-abcdefg0] has entered the All Paths Down Timeout state after being in the All Paths Down state for 140 seconds. I/Os will now be fast failed.
If you are hitting these issues than VMware recommends reverting back to vSphere 5.5. Please monitor the following KB closely for more details and hopefully a fix in the near future: http://kb.vmware.com/kb/2076392
How does vSphere recognize an NFS Datastore?
This question has popped up various times now, how does vSphere recognize an NFS Datastore? This concept has changed over time and hence the reason many people are confused. I am going to try to clarify this. Do note that this article is based on vSphere 5.0 and up. I had a similar article a while back, but figured writing it in a more explicit way might help answering these questions. (and gives me the option to send people just a link :-))
When an NFS share is mounted a unique identifier is created to ensure that this volume can be correctly identified. Now here comes the part where you need to pay attention, the UUID is created by calculating a hash and this calculation uses the “server name” and the folder name you specify in the “add nfs datastore” workflow.

This means that if you use “mynfserver.local” on Host A you will need to use to use the exact same on Host B. This also applies to the folder. Even “/vols/vol0/datastore-001” is not considered to be the same as “/vols/vol0/datastore-001/”. In short, when you mount an NFS datastore make absolutely sure you use the exact same Server and Folder name for all hosts in your cluster!
By the way, there is a nice blogpost by NetApp on this topic.