I received two questions this week around partition scenarios where after the failure has been lifted some VMs display the error message “vSphere HA virtual machine failed to failover”. The question that then arises is: why did HA try to restart it, and why did it fail? Well, first of all, this is an error that in most cases you can safely ignore. There’s a KB on the topic which gives a bit of detail to be found here, but let me explain also in a bit more depth.
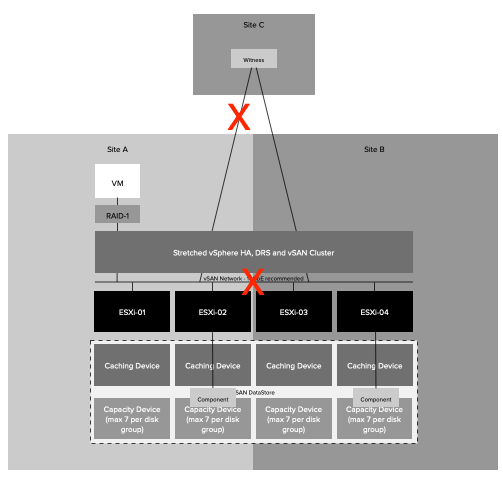
In a partitioning scenario, each partition will have its own primary node. If there is no form of communication (datastore/network) possible, what the HA primary will do is it will list all the VMs that are currently not running within that partition. It will also want to try to restart those VMs. A partition is extremely uncommon in normal environments but may happen in a stretched cluster. In a stretched cluster when a partition happens a datastore only belongs to 1 location. The VMs which appear to be missing typically are running in the other location, as typically the other location will have access to that particular datastore. Although the primary has listed these VMs as “missing and need to restart” it will not be able to do this. Why? It doesn’t have access to the datastore itself, or when it has access to the datastore the files are locked as the VMs are still running. As a result, this will, unfortunately, be reported as a failed failover. Even though the VM was still running and there was no need for a failover. So if you hit this during certain failure scenarios, and the VMs were running as you expected, you can safely ignore this error.