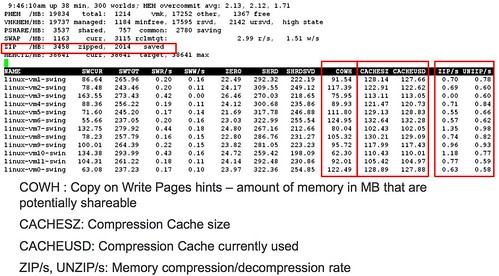
When we wrote the HA/DRS book both Frank and I were still very much in an “ESX Classic” mindset. Over the last weeks I had questions around resilient network configurations for ESXi. I referred people back to the book but the comments that I got were that the examples were very much ESX Classic instead of ESXi. Now in my opinion the configuration looks very much the same except that “Service Console” will need to be replace with “Management Network” but I figured I might as well just document my preference for a resilient ESXi Management Network as I needed to do it anyway as part of an update of the book to a future version of vSphere.
In our book we give two examples, one of which is the simple version with a single “Service Console Network” and one with a dual “Service Console Network” configuration. Now I figured I could update both but I’d rather do just one and explain why I prefer to use this one. The one that I have picked is the single “Management Network” setup. The main reason for it being is the reduced complexity that it brings and on top of that multiple Management Networks will make sense in an environment where you have many NICs and Switches but with all these converged architectures flying around it doesn’t really make sense anymore to have 4 virtual links when you only have 2 physical. Yes I understand that something can happen to a subnet as well, but if that is the case you have far bigger problems than your HA heartbeat network failing. Another thing to keep in mind is that you can also mitigate some of the risks of running into a false positive by selected a different “Isolation Response”, typically we see these set to “Leave Powered On”.
The below is an excerpt from the book.
Although there are many configurations possible and supported we recommend a simple but highly resilient configuration. We have included the vMotion (VMkernel) network in our example as combining the Management Network and the vMotion network on a single vSwitch is the most commonly used configuration and an industry accepted best practice.
Requirements:
- 2 physical NICs
- VLAN trunking
Recommended:
- 2 physical switches
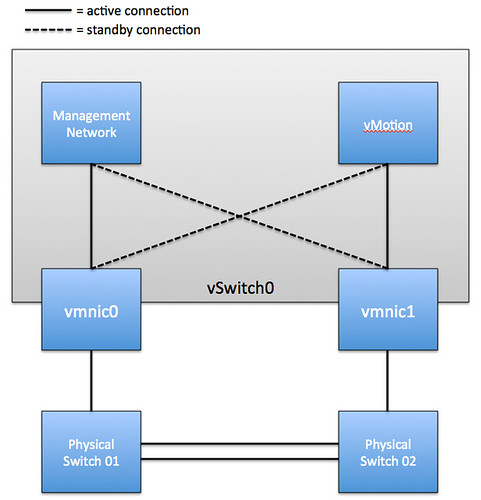
The vSwitch should be configured as follows:
- vSwitch0: 2 Physical NICs (vmnic0 and vmnic1)
- When multiple physical PCI devices are available make sure to use a port of each to increase resiliency
- 2 Portgroups (Management Network and vMotion VMkernel)
- Management Network active on vmnic0 and standby on vmnic1
- vMotion VMkernel active on vmnic1 and standby on vmnic0
- Failback set to No
Each portgroup has a VLAN ID assigned and runs dedicated on its own physical NIC; only in the case of a failure it is switched over to the standby NIC. We highly recommend setting failback to “No” to avoid chances of a false positive which can occur when a physical switch routes no traffic during boot but the ports are reported as “up”. (NIC Teaming Tab)
Pros: Only 2 NICs in total are needed for the Management Network and vMotion VMkernel, especially useful in Blade environments. This setup is also less complex.
Cons: Just a single active path for heartbeats.
The following diagram depicts the active/standby scenario:
To increase resiliency we also recommend implementing the following Advanced Settings where the ip-address for “das.isolationaddress” should be a “pingable” device which is reachable by the ESXi hosts, preferably on the same subnet with as little hops as possible:
das.isolationaddress = <ip-address> das.failuredetectiontime = 20000