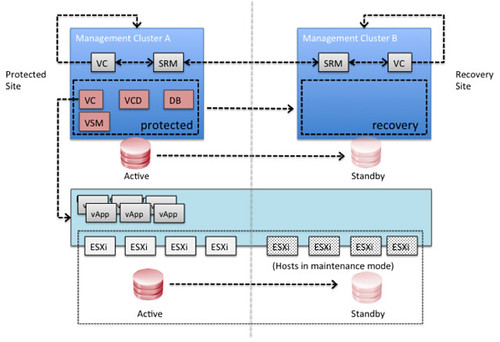
I know some of you have been waiting for this so I wanted to share some early results. I was in the UK last week and we managed to get an environment configured using persistent linked clone virtual desktops with View. We also managed to fail-over and fail-back desktops between two datacenters. The concepts is really similar to the vCloud Director DR concept.
In this scenario Site Recover Manager will be leveraged to fail-over all View management components. In each of the sites it is required to have a management vCenter Server and an SRM Server which aligns with standard SRM design concepts. Since it is difficult to use SRM for View persistent desktops there is no requirement to have an SRM environment connecting to the View desktop cluster’s vCenter Server. In order to facilitate a fail-over of the View desktops a simple mount of the volume is done. This could be using ‘esxcfg-volume -m’ for VMFS or using a DNS c-name mounting the NFS share after point the alias to the secondary NAS server.
What would the architecture look like? This is an oversimplified architecture, of course … but I just want to get the message across:
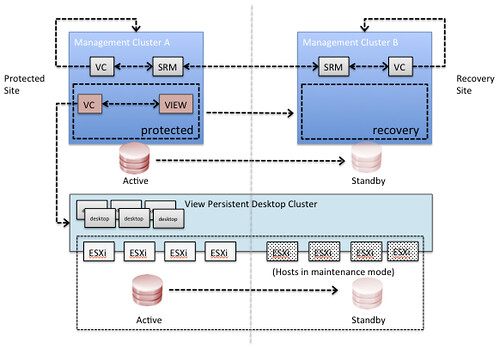
What would the steps be?
- Fail-over View management environment using SRM
- Validate all View management virtual machines are powered on
- Using your storage management utility break replication for the datastores connected to the View Desktop Cluster and make the datastores read/write (if required by storage platform)
- Mask the datastores to the recovery site (if required by storage platform)
- Using ESXi command line tools mount the volumes of the View Desktop Cluster cluster on each host of the cluster
- esxcfg-volume –m <;volume ID>;
or - point the DNS CNAME to the secondary NAS server and mount the NAS datastores
- Validate all volumes are available and visible in vCenter, if not rescan/refresh the storage
- Take the hosts out of maintenance mode for the View Desktop Cluster (or add the hosts to your cluster, depending on the chosen strategy)
- In our tests the virtual desktops were automatically powered on by vSphere HA. vSphere HA is aware of the situation before the fail-over and will power-on the virtual machines according to the last known state
These steps have been validated this week and we managed to successfully fail-over our desktops and fail them back. Keep in mind that we only did these tests two or three times, so don’t consider this article to be support statement. We used persistent linked clones as that was the request we had at that point, but we are certain this will work for the various different scenarios. We will extend our testings to include various other scenarios.
Cool right!?