I wrote a vSAN HCI Mesh Considerations blog post a few weeks ago. Based on that post I received some questions, and one of the questions was around vSphere HA configurations. Interestingly I also had some internal discussions around how vSAN HCI Mesh and HA were integrated. Based on the discussions I did some testing just to validate my understanding of the implementation.
Now when it comes to vSphere HA and vSAN the majority of you will be following the vSAN Design Guide and understand that having HA enabled is crucial for vSAN. Also when it comes to vSAN configuring the Isolation Response is crucial, and of course setting the correct Isolation Address. However, so far there’s been an HA feature which you did not have to configure for vSAN and HA to function correctly, and that feature is VM Component Protection aka APD / PDL responses.
Now, this changes with HCI Mesh. Specifically for HCI Mesh the HA and vSAN team have worked together to detect APD (all paths down) down scenarios! When would this happen? Well if you look at the below diagram you can see that we have “Client Clusters” and a “Server Cluster”. The “Client Cluster” consumes storage from the “Server Cluster”. If for whatever reason a host in the “Client Cluster” loses access to the “Server Cluster”, it results in the VMs on that host consuming storage on the “Server Cluster” to lose access to the datastore. This is essentially an APD (all paths down) scenario.
.png "vSphere HA configuration for HCI Mesh!")
Now, to ensure the VMs are protected by HA for this situation you only need to enable the APD response. This is very straight-forward. You simply go to the HA cluster settings and set the “Datastore with APD” setting to either “Power off and restart VMs – Conservative” or “Power off and restart VMs – Aggressive”. The difference between conservative and aggressive is that with conservative HA will only kill the VMs when it knows for sure the VMs can be restarted, wherewith aggressive it will also kill the VMs on a host impacted by an APD while it isn’t sure it can restart the VMs. Most customers will use the “Conservative Restart Policy” by the way.
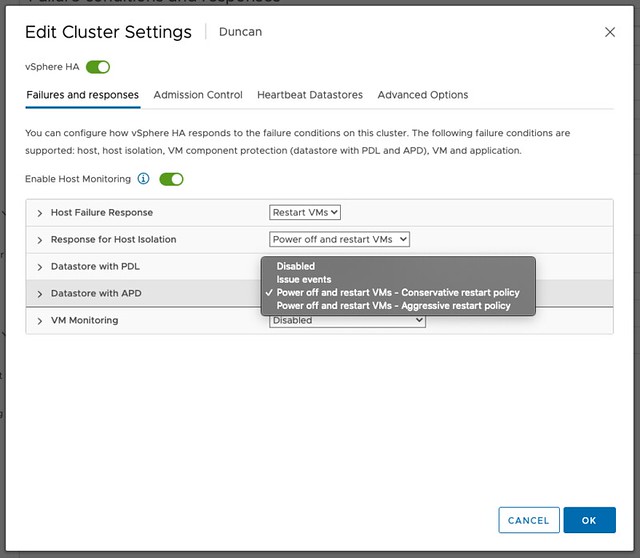
As I also mentioned in the HCI Mesh Considerations blog, one thing I would like to call out is the timing for the APD scenario: The APD is declared after 60 seconds, after which the APD response (restart) is triggered automatically after 180 seconds. Mind that this is different than with an APD response with traditional storage, as with traditional storage it will take 140 seconds before the APD is declared. You can, of course, in the log file see that an APD is detected, declared and VMs are killed as a result. Note that the “fdm.log” is quite verbose, so I copied only the relevant lines from my tests.
APD detected for remote vSAN Datastore /vmfs/volumes/vsan:52eba6db0ade8dd9-c04b1d8866d14ce5 Go to terminate state for VM /vmfs/volumes/vsan:52eba6db0ade8dd9-c04b1d8866d14ce5/a57d9a5f-a222-786a-19c8-0c42a162f9d0/YellowBricks.vmx due to APD timeout (CheckCapacity:false) Failover operation in progress on 1 Vms: 1 VMs being restarted, 0 VMs waiting for a retry, 0 VMs waiting for resources, 0 inaccessible vSAN VMs.
Now for those wondering if it actually works, of course, I tested it a few times and recorded a demo, which can be watched on youtube (easier to follow in full screen), or click play below. (Make sure to subscribe to the channel for the latest videos!)
I hope this helps!
 I’ve had a bunch of customers asking the past couple of weeks when vSphere / vCenter 7.0 U1 would be supported with SRM. Yesterday (22nd of October) vCenter Server 7.0 U1a was released and this release introduced support/compatibility with SRM. For those wondering why it wasn’t supported, there was an issue with vCLS and SRM which had to be fixed first. So if you are one of those customers who runs the latest and greatest version of vSphere in combination with SRM you can now move to 7.0 U1a. If you haven’t seen the details yet of the release you can find it here:
I’ve had a bunch of customers asking the past couple of weeks when vSphere / vCenter 7.0 U1 would be supported with SRM. Yesterday (22nd of October) vCenter Server 7.0 U1a was released and this release introduced support/compatibility with SRM. For those wondering why it wasn’t supported, there was an issue with vCLS and SRM which had to be fixed first. So if you are one of those customers who runs the latest and greatest version of vSphere in combination with SRM you can now move to 7.0 U1a. If you haven’t seen the details yet of the release you can find it here: considerations, questions and answers.")