Internally some of my focus has been shifting, going forward I will spend more time on edge computing besides vSAN. Edge (and IoT for that matter) has had my interest for a while, and when VMware announced an edge project I was intrigued and interested instantly. At VMworld US the edge computing efforts were announced. The name for the effort is Project Dimension. There were several sessions at VMworld, and I would recommend watching those if you are looking for more info then provided below. The session out of which I took most of the below info was IOT2539BE, titled “Project Dimension: the easy button for edge computing” by Esteban Torres and Guru Shashikumar. Expect more content on Project Dimension in the future as I start getting involved more.
What is Project Dimension? What discussed at VMworld was the following:
- A new VMware Cloud service; starting at edge locations
- Enable enterprises to consume compute, storage, and networking at the edge like they consume public cloud
- VMware will work with OEM partners to deliver and manage hyperconverged appliances in edge locations
- All appliances will be managed by VMware via VMware Cloud
So what does it include? Well as mentioned it includes hardware, the type etc hasn’t been mentioned, but it was said that Dell and Lenovo are the first two OEMs to support Project Dimension. This hyperconverged solution will include:
- vSphere
- vSAN
- Velocloud
This solution will be managed by a “hybrid cloud control plane” as it is referred to, all by VMware. Architecturally this is what the service will look like:
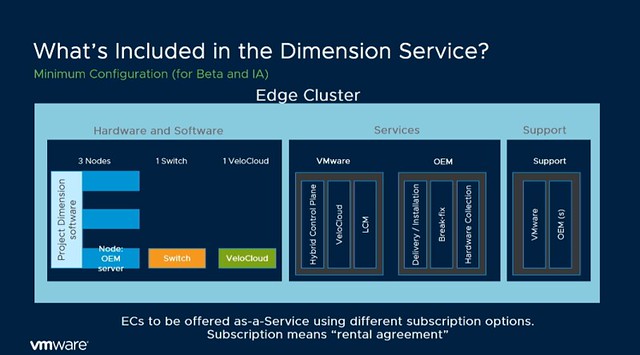
Now what I found very interesting is that during the session someone asked about the potential for Dimension in on-prem datacenters, and the answer was: “Edge is where we are beginning, but the long-term plan is to offer the same model for data centers as well”. Some may notice that in the above list and diagram NSX is missing, as mentioned during the session, this is being planned for, but preferably will be a “lighter” flavor. What also stands out is that the HCI solution includes not only compute but also networking (switches and SD-WAN appliance).
Now, what is most interesting is the management aspect, VMware and the OEM partner will do the full maintenance/lifecycle management for you. This means that if something breaks the OEM will fix it, you as a customer however always contact VMware, single point of contact for everything. If there’s an upgrade then VMware will go through that motion for you. Every edge cluster for instance also has a vCenter Server instance, but you as an administrator/service owner will not be managing that vCenter Server instance, you will be managing the workloads that run in that environment. This to me makes sense, as when you scale out and potentially have hundreds or thousands of locations you don’t want to spend most of your time managing the infra for that, you want to focus on where the company’s revenue is.
Now getting back to the maintenance/upgrades. How does this work, how do you know you have sufficient capacity to allow for an upgrade to happen? VMware will also ensure this is possible by doing some form of admission control, which prevents you to claim 100% of the physical resources. Another interesting thing mentioned is that Dimension will allow you to chose when the upgrade or patches will be applied. In most environments maintenance will have an impact on workloads in some shape or form, so by providing blackout dates a peak season/time can be avoided.
From a hardware point of view and procurement perspective, this service is also different then you are used to. The services will be on a subscription basis. 1 year or 3-year reserved edge clusters, or more of course. And from a hardware perspective, it kind of aligns with what you typically see in the cloud: Small, Medium or Large instance. Which then refers to the number of resources you get per node. Starting with 3 nodes, of course, have the ability to scale up and potentially start smaller than 3 nodes in the future. The process in terms of sign up / procurement is displayed in the diagram below, delivery would be within 1-2 weeks, which seems extremely fast to me.
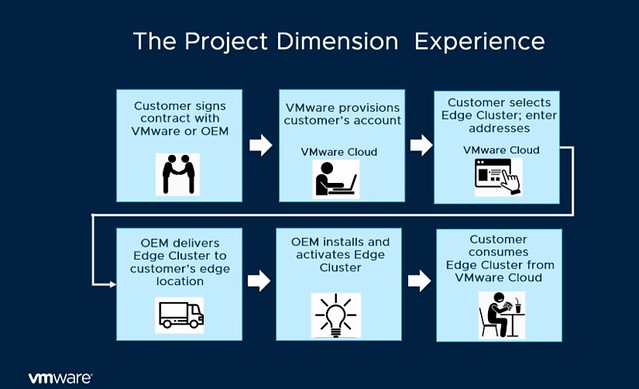
What I also found interesting was the mention of a “try and buy” option, you pay for 3 months and if you like it you keep it, and your 3 months contract will go to 1 year (or so) automatically.
At this point you may be asking: why is VMware doing this? Well, it is pretty simple: demand and industry changes. We are starting to see a clear trend, more and more workloads are shifting closer to the consumer. This allows our customers to process data faster and more importantly respond faster to the outcome, and of course, take action through machine learning. But the biggest challenge customers have is consistently managing these locations at a global scale, and this is what Project Dimension should solve. This is not just a challenge at the edge, but across edge, on-prem and public cloud if you ask me. There are so many moving parts, various different tools, and interfaces, which just makes things overly complex.

So what is VMware planning on delivering with Project Dimension? Consistently, reliable and secure hyperconverged infrastructure which is managed through a Cloud Control Plane (single pane of glass management for edge environments) and edge-to-cloud connectivity through Velocloud SD-WAN. (Management traffic for now, but “edge to edge” and “edge to on-prem” soon!) There’s a lot of innovation happening at the back-end when it comes to managing and maintaining 1000s of edge locations, but you as a customer are buying simplicity, reliability, and consistency.
Please note, Project Dimension is in beta, and the team is still looking for beta customers. You need to have a valid use case, as I can see some of you thinking “nice for a home lab for a couple of weeks”, but that, of course, is not what the team is looking for. For those who have a good use case, please go to the product page and leave your details behind: http://vmwa.re/dimension
 Over the past couple of months Frank, Niels and I have worked ferociously to update the vSphere Clustering Deep Dive. Some of the material was already brought up to date to vSphere 6.0 U2, but the majority was never updated after vSphere 5.1. As you can imagine, this was a tremendous undertaking. Not only did we need to validate every sentence, all diagrams needed to be updated, and with the introduction of the HTML-5 Client also all screenshots had to be retaken.
Over the past couple of months Frank, Niels and I have worked ferociously to update the vSphere Clustering Deep Dive. Some of the material was already brought up to date to vSphere 6.0 U2, but the majority was never updated after vSphere 5.1. As you can imagine, this was a tremendous undertaking. Not only did we need to validate every sentence, all diagrams needed to be updated, and with the introduction of the HTML-5 Client also all screenshots had to be retaken. I wrote a blog post a while back about
I wrote a blog post a while back about