First session of the day at 08:30: “The Evolution of vSAN”. Vijay Ramachandran and Christos Karamanolis will be talking where vSAN came from and where it will be going towards in the upcoming years. Vijay started out laying the foundation, talking about what HCI is, what the benefits are and where it fits in.
I think Vijay was spot on, HCI simplifies operating storage / infrastructure as the various layers have converged and the single management pane simplifies your life. Especially when using an appliance model. I liked how Vijay explained the difference between vSAN and competitive solutions. The big difference is the fact that for competitors the storage piece is a separate entity(virtual appliance), with vSAN your storage stack comes as part of vSphere.
Next Vijay discussed all the different use cases and customer types. He showed some new survey data, and it showed that 65% of our customers use vSAN for business critical apps (Oracle, SQL, Exchange, SAP etc). With the two other big use cases being Horizon View/Citrix Xen Desktop but also for Management Clusters and DMZ. Some of the newer use cases we are starting to see are NoSQL solutions.

Next Performance was discussed, shocking how vSAN 6.6 bumped performance with 60% even when all data services are enabled. 60% is a lot higher than I expected, especially as this wasn’t just an increase in IOPS but 6.6 also brought a decrease in latency! Before Vijay handed it over, he mentioned the latest vSAN Customer Count: 10k!
Up now Christos, this will be the forward looking part of the session. Christos kicks off talking about three key tends. First, the new storage devices out in the market: NVMe and NVDIMM. These faster devices in most cases will require a re-architecture or at a minimum think about how you leverage these devices. NVMe devices are becoming more affordable and provide extremely low latency and high IOPS, and non-volatile memory even tops that. How will this change the architecture for vSAN? Secondly, the growth of public cloud, is there a way HCI can leverage that? And thirdly, cloud native apps. How do these new application architectures and delivery methods change the storage requirements?
Christos briefly discussed a potential future change for vSAN which is the convergence of the caching tier and the capacity tier… Providing essentially a single tier of storage devices in your vSAN environment, where vSAN will automatically tier data between devices. You could imagine meta-data residing on NVDIMM or NVMe while “cold data” resides on the “lower tiers”. No longer should it be needed to define a caching layer and a capacity layer. Which should result in better performance and better capacity utilization.
Next point being discussed is the operational aspect. Functionality introduced recently have made the life of customers easier, things like vSAN and VUM, S.M.A.R.T support, PowerCLI cmlets, vRA / VROps and LogInsight advanced support and integration. Next Christos demoed one of the latest addition, the Performance Diagnostic feature that is part of vSAN 6.6.1. If you haven’t seen it yet, watch my demo on youtube.

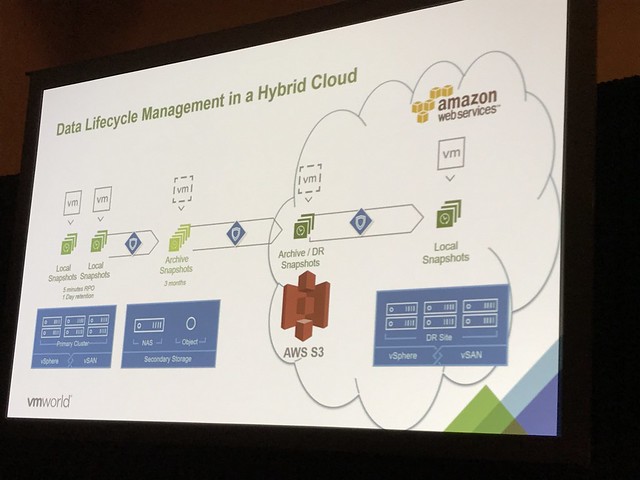
Next Christos discusses how vSAN is used in AWS and how hybridity is achieved leveraging Hyper-Converged architectures. Enterprise grade storage is needed in AWS to provide the ability to use DRS, HA and other essential vSphere functionality. This is where vSAN came in to play. This provides you a very similar experience in the cloud as on-premises. But of course there’s a big benefit of leveraging VMware Cloud on AWS. In the future you can expect an extremely easy scalable storage stack. Compute already scales in a simple manner, but what if you do not need extra compute and just want to add storage, this will be possible soon. Not only will you be able to add storage, but you will also be able to connect to all native AWS Services. You can imagine that a great use case would be “Disaster Recover”. What you can expect from VMware in the near future is a DR as a Service solution, allowing you to failover from your local datacenter in to VMware Cloud on AWS. This offering would be leveraging SRM and vSphere Replication. But on top of that a new snapshotting mechanism is developed, which will allow even for a more flexible architecture. Not just the ability to replicate to vSAN, NFS or something like data domain. But also store your data in S3 in AWS, and when a recovery needs to occur, without having an environment pre-provisioned in VMware Cloud on AWS, trigger a fail-over when it needs to occur and have a VMware Cloud on AWS infrastructure being spun out and your VMs being recovered from S3 in to that environment.
Last topic of the session was Cloud Native Apps. Christos discussed Project Hatchway. Project Hatchway provides the Docker Volume Service and the vSphere Cloud Provider for Kubernetes. On top of that vSAN will be optimized for “share-nothing” applications. As mentioned in my summary of STO1490, these enhancements will allow you to co-locate data and compute when you have “FTT=0” configured even. Also, sequential I/O will be improved in future releases, as in many cases these share-nothing applications are highly sequential workloads.
Great session, not sure it was recorded, but if it was… watch it online when it is released!