“I have memory pages swapped out to disk, can vSphere swap them back in to memory again” is one of those questions that comes up occasionally. A while back I asked the engineering team why we don’t “swap in” pages when memory contention is lifted. There was no real good answer for it other than it was difficult to predict from a behavioural point of view. So I asked what about doing it manually? Unfortunately the answer was: well we will look in to it but it has no real priority it this point.
I was very surprised to receive an email this week from one of our support engineers, Valentin Bondzio, that you can actually do this in vSphere 6.0. Although not widely exposed, the feature is actually in there and typically (as it stands today) is used by VMware support when requested by a customer. Valentin was kind enough to provide me with this excellent write-up. Before you read it, do note that this feature was intended for VMware Support. While it is internally supported, you’d be using it at your own risk, and consider this write-up to be purely for educational purposes. Support for this feature, and exposure through the UI, may or may not change in the future.
By Valentin Bondzio
Did you ever receive an alarm due to a hanging or simply underperforming application or VM? If yes, was it ever due to prolonged hypervisor swap wait? That might be somewhat expected in an acute overcommit or limited VM / RP scenario but very often the actual contention happened days, weeks or even month ago. In those scenarios, you were just unlucky enough that the guest or application decided to touch a lot of the memory that happened to be swapped out around the same time. Which until this exact time you either didn’t notice or if you did, didn’t pose any visible threat. It just happened to be idle data that resided on disk instead of in memory.
The notable distinction being that it is on disk with every expectation of it being in memory, meaning a (hard) page fault will suspend the execution of the VM until that very page is read from disk and back in memory. If that happens to be a fairly large and contiguous range, even with gracious pre-fetching from the ESXi, you’ll might experience some sort of service unavailability.
How to prevent this from happening in scenarios where you actually have ample free memory and the cause of contention is long resolved? Up until today that answer would be to power cycle your VM or using vMotion with local swap store to asynchronously page in the swapped out data. For everyone that is running on ESXi 6.0 that answer just got a lot simpler.
Introducing unswap
As the name implies, it will page in memory that has been swapped out by the hypervisor, whether it was actual contention during an outage or just an ill-placed Virtual Machine or Resource Pool Limit. Let’s play through an example:
A VM experienced a non-specified event (hint, it was a 2GB limit) and now about 14GB of its 16GB of allocated memory are swapped out to the default swap location.
# memstats -r vm-stats -u mb -s name:memSize:max:consumed:swapped | sed -n '/ \+name/,/ \+Total/p' name memSize max consumed swapped ----------------------------------------------------------- vm.449922 16384 2000 2000 14146
The cause for the contention was remediated and now we want to prevent that the VM touches any of that swapped out memory and experience a prolonged or even just multiple short intermittent freezes.
name memSize max consumed swapped ----------------------------------------------------------- vm.449922 16384 -1 2000 14146
At first, we just dip our toes into the water, so we decide to just unswap two GBs.
# localcli --plugin-dir=/usr/lib/vmware/esxcli/int vm process unswap -w 449922 -s 2 -u GB
We follow the vmkernel.log in another SSH session to verify the operation:
# tail -F /var/log/vmkernel.log | grep Swap 2016-05-30T08:09:14.379Z cpu4:1042607)Swap: vm 449923: 3799: Starting prefault for the reg file 2016-05-30T08:11:23.280Z cpu2:1042607)Swap: vm 449923: 4106: Finish swapping in reg file. (faulted 524288 pages, pshared 0 pages). Success.
Our sceptic nature makes us verify with memstats too:
name memSize max consumed swapped ----------------------------------------------------------- vm.449922 16384 -1 4052 12093
That seemed to work pretty well! If we had just thought about verifying that the guest wasn’t affected by this … We’ll track it for the remainder of swap though. From a VM in the same broadcast domain we run a ping against our test subject, win_stress_02:
# node=win_stress_02; while true; do sleep 1; ping=$(ping -W 1 -c 1 ${node} | sed -n "s/.*bytes from .*:.*time=\(.*\)/ \1/p"); if [ "$ping" ]; then echo $(date -u +"%Y-%m-%dT%H:%M:%S") ${ping}; else echo -e $(date -u +"%Y-%m-%dT%H:%M:%S") drop; fi; done | tee /tmp/stress_ping_tee.txt
2016-05-30T08:14:53 6.24 ms
2016-05-30T08:14:54 0.616 ms
2016-05-30T08:14:55 0.697 ms
2016-05-30T08:14:56 0.586 ms
2016-05-30T08:14:57 0.554 ms
2016-05-30T08:14:58 0.742 ms
2016-05-30T08:14:59 6.06 ms
2016-05-30T08:15:00 0.806 ms
2016-05-30T08:15:01 0.743 ms
2016-05-30T08:15:02 0.642 ms
(…)
and:
# localcli --plugin-dir=/usr/lib/vmware/esxcli/int vm process unswap -w 449922
We are keeping track of the progress via the VM’s performance chart in vCenter:
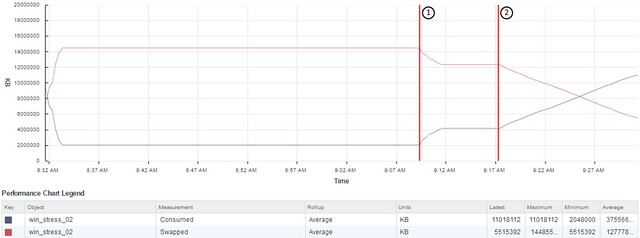
But we also follow vmkernel.log:
# tail -F /var/log/vmkernel.log | grep Swap (…) 2016-05-30T08:17:12.013Z cpu7:1042886)Swap: vm 449923: 3799: Starting prefault for the reg file 2016-05-30T08:45:27.632Z cpu1:1042886)Swap: vm 449923: 4106: Finish swapping in reg file. (faulted 3094455 pages, pshared 0 pages). Success.
memstats confirms, no more current swap:
name memSize max consumed swapped
-----------------------------------------------------------
vm.449922 16384 -1 16146 0
Was there any serious impact though, how can we check? It is unlikely after all that the users of a VM called “win_stress_02” will complain...While there was some swap wait, it was minimal given that we just swapped in 14 GB of memory. For a more subjective method we still have our ping! (that we completely forgot about until now...) Let’s count the number of pings during which unswap paged in 12 GB:
# sed -n '/2016-05-30T08:17/,/2016-05-30T08:45/p' /tmp/stress_ping_tee.txt | wc -l 1646
How many of those were 10ms or above?
# sed -n '/2016-05-30T08:17/,/2016-05-30T08:45/p' /tmp/stress_ping_tee.txt | awk '$2 !~ /^[0-9]\./' | wc -l 57
And how many dropped (with a 1 second timeout)?
# sed -n '/2016-05-30T08:17/,/2016-05-30T08:45/p' /tmp/stress_ping_tee.txt | grep -c drop 8
That is 3.5% and 0.5% respectively, not too shabby given the gruelling alternatives! (the baseline for a ping between those two VMs without any unswap operation is 0.29% and 0.21% respectively. Hey, it’s a lab after all)
To summarize, unswap provides an easy way to swap in parts or all VM current swap with minimal, near unnoticeable, performance impact. In the _very_ unlikely scenario that it, I don’t know, for example does crash your VM or affects your workload noticeably, please leave your feedback here. Not that this has happened to me so far but I won’t make promises (again, it is strictly speaking not “customer usage supported”, so no support requests).
How would the kernel choose which pages to swap-in ? AFAIK, there’s no info about when each paged was s.o., so no way to do LIFO (would that be LOFI, last out first in 🙂 Unless you swap in everything, isn’t this a roulette ?
Does it take current I/O load into consideration ?
Reading this got me thinking that some kind of “soft reserve” would be a nice idea, kind of another priority to use pages if you are really constrained, and then you get your reserve back when the tide passes, but that would need housekeeping records, to know what to get back. W/o this knowledge, I don’t see a real use case, do you ?
The pages were swapped out at random so why does it matter in what order they are swapped in? ESXi doesn’t have any knowledge of whether the memory was out of the working set of an application or just from the standby list, all you are doing is to reduce the probability of a memory access in the guest causing a disk access (in the critical path). So if you don’t have enough free memory on the host to swap in all of the VMs current swap, if there is enough to do half you just reduced the potential impact / the probability of one by 50%.
Well, I tend to forget that in fact the active memory state is maintained only for metrics on a sample, and that the hypervisor does not use that information to choose which page to swap out. But even so, if the page was hot, it would be demand paged in, so the pages that stay on swap, I would presume, are not from the WS (even if the hypervisor is in HARD state, random pages out vs WS pages in end up sorting what pages stay in disk).
I’m reluctant to accept that reading half of the pages will give you half of the chances that your next page fault will be eliminated (i.e. that you read the next to be needed page with a 50% chance).
I fail to see a situation where there is free memory (for days ?) and needed pages are not just demand paged in. After all, if they where needed, the only difference would be the efficiency of one method over the other, i.e., the reduced context switches between world and kernel, right ?
Then I guess this isn’t for you, I know I have plenty of customers who love this, they prefer to swap in all the memory when pressure is down instead of incurring that hit the next time a page is needed, which you don’t know when it will be. Either way, not all functionality offered in a product will be equally valuable to every one 🙂
I guess some of what you are saying is lost in translation because I’m not entirely sure what point you are trying to make. Let’s maybe define working set first, everything that has a vP -> pP mapping, i.e. “Working Set” on Windows, “resident” on Linux. I’m making the assumption that things in the Working Set have a higher chance of being touched compared to things on the “Standby List” (Windows, cache on Linux), that doesn’t have to be true in all scenarios of course but just because something is in the Working Set also doesn’t mean that it is hot and touched within a time frame that wouldn’t allow to unswap it first. Still, the whole point is that _any_ swapped out page _could_ be touched at a point in the future causing the guest to be _stunned_ until that page is back in memory. Unswap does that outside of the critical path, i.e. without any serious performance implication.
As for the 50% chance, if I randomly drop a coin in a football field, what are my chances to find it in either one?
Let me walk you through an example:
You had some contention and about a GB of swapped memory, let’s just assume that this is all on the Standby List so no current process needs it and there is no impact at the second. The contention situation is resolved (host failure) and everything is performing for days without issues. Friday night, your in guest backup agent (because you don’t want to risk stun times with snapshots) has a full backup scheduled. It is quite the memory hog and needs more than is available on the free and zero list. So the OS drops stuff from the Standby List to free -> zero and give to the application that demands more memory. When the OS (by chance) touches a pages that it thinks is in memory but is swapped out, the guest will stop executing until the page is read in. Let’s further assume the worst case scenario, no pre-fetching, everything is random but at least we grant it on OK 5ms read latency. If we need to swap in 500MB, that is 512500 pages * 5 ms, so 11 minutes of swap wait, i.e. the guest is not executing.
If that would have been unswaped via the described mechanism, the impact during that time might have been a few seconds / dropped pings. If we could have only unswapped half of the swapped out memory, the impact when the guest wants the other 50% would have been reduced to 5.5 minutes.
The example is of course very extreme, there is usually a healthy amount of pre-fetching but we would probably still talk about at least half of what I outlined. And again, the whole point of this article is to prevent _the future possibility_ of swap wait by unswaping it before it comes to it.
Last time this happened to me was when I let vCenter choose how many hosts to remediate in parallel. Bad idea. I had to reboot 100+ VM’s after that, even though I stopped the task asap and the stretch cluster had 50% free resources then. Nice to see that there now might be a way to workaround a reboot.
Thanks! This shows the expertise the support team have!
Is there something like this for version < 6.0?