I just added a real life RAID penalty example to the IOps article. I know Sys Admins are lazy, so here’s the info I just added:
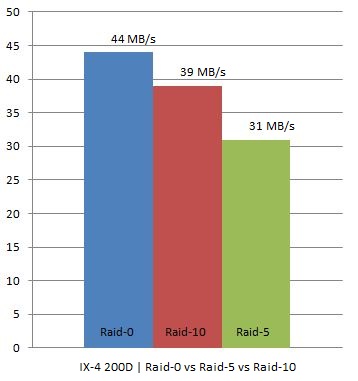
I have two IX4-200Ds at home which are capable of doing RAID-0, RAID-10 and RAID-5. As I was rebuilding my homelab I thought I would try to see what changing RAID levels would do on these homelab / s(m)b devices. Keep in mind this is by no means an extensive test. I used IOmeter with 100% Write(Sequential) and 100% Read(Sequential). Read was consistent at 111MB for every single RAID level. However for Write I/O this was clearly different, as expected. I did all tests 4 times to get an average and used a block size of 64KB as Gabes testing showed this was the optimal setting for the IX4.
In other words, we are seeing what we were expecting to see. As you can see RAID-0 had an average throughput of 44MB/s, RAID-10 still managed to reach 39MB/s but RAID-5 dropped to 31MB/s which is roughly 21% less than RAID-10.
I hope I can do the “same” tests on one of the arrays or preferably both (EMC NS20 or NetApp FAS2050) we have in our lab in Frimley!
I’ve had great success using this test file for IOmeter as a starting point for this sort of thing:
http://www.mez.co.uk/OpenPerformanceTest.icf
It defines some good baseline tests: a)100% read @ 32K block size, b) 60% Random, 65% Read @ 8K block, c) 50% Read @ 32K block d) 100% Random/70% Read @ 8K Block. I run this against various LUNs presented to a host machine. I normally present a RAID0, RAID1 and RAID5 LUN to the host and run through this test — ideally, before the array goes into production.
It gives a good idea of the best (100% sequential read @ large blocks) and worst (100% random r/w with small blocks).
@Doug Baer 32Kb is useless and doesn’t represent real world load… Preferably test 4Kb, default NTFS allocation unit size, or 8Kb for an Exchange environement, try 64Kb for a SQL env., try 256Kb for a backup/restore load … Check Chad Sakac post at http://virtualgeek.typepad.com/virtual_geek/2008/09/howto—benchma.html for really nice tips on benchmarking.
100% Sequential Reads and Writes with a large block (64K) size is the “best case” example. That’s because this workload tends to fill stripes and minimize the RAID penalty. Even in this best case scenario, the write penalty of the various RAID types is readily apparent. A far more realistic “real world” workload would be half reads and half writes, 100% random, and an 8K IO size. That’s especially true for workloads on virtualized platforms. When you coalesce and combine the workloads of many applications running in a virtualized environment, and throw in some read caching on the virtualization platform, you end up with a random IO pattern close to a 1:1 read/write ratio.
John
I agree John, I think I mis labeled the post. it should be “non theoretical proof of RAID penalty” instead of “real life example” as the test used is most definitely best case and was merely used to point out that there is a penalty and shows what the effect can be.
This is interesting, and important to know. At the same time, I would be personally reluctant to trade the security of RAID for ~20% performance in IO unless I knew I was solving a problem. In other words, at what point does the performance gap effect user experience or otherwise diminish the job the system was designed for?
I agree with Josh. With regard to the other comments, I’ve found it difficult to model any sufficiently complex production workload, regardless of the block sizes I use in the tests — especially when server virtualization is involved. In my experience, the testing numbers out of their own context are as meaningless as the array vendors’ published numbers.
If your goal is to obtain comparative numbers for various arrays or LUN types on the same array, choose some tests and run the same tests across the board. If your goal is to get absolutely “correct” numbers for a given environment/workload/configuration, you’ll have to create a much better I/O model than simply setting a block size and randomness. Ultimately, you will need to measure performance of the actual workloads in your environment.